In an era of online-everything, you probably think that your data is already dynamic. It certainly has come a long way from printed stock tables—live market data, instant access to customer details and contract terms, vast arrays of economic data and other useful measures.
Dynamic data does not just refer to the ability to call up something on a screen instead of on paper. It also means keeping the data connected to models that give the data meaning. Data that isn’t fully integrated with analytics, models, and other calculations risks getting stale.
Lakes of Static Data are Everywhere
You can store large amounts of data in different ways. In most organizations, data lakes and data warehouses are large repositories of static, precalculated data that can be queried and displayed. The values contained within them do not change unless other programs, models, analytics, or applications outside of the data lake extract some data, manipulate it, display it, modify it, and then store it back in the data lake.
Multiple pieces of software from different vendors or in-house tech silos are often involved in these static data manipulations, creating efficiency issues when moving data from storage to analysis to visualization and back. Another concern with this type of segregated model is stability and governance of the data flow. Organizations need to monitor and control not just access and authorizations for the data, but also for the programs that interact with the data. Having these separate increases the risks of not knowing whether the stored data is correct, either because it hasn’t been updated when necessary, or because it is not clear who or what made the change. And the lack of historical references makes it difficult to audit earlier decisions.
Dynamic Data Keeps the Values Alive
Beacon’s dynamic data architecture uses a dependency graph to understand and maintain relationships between data values. These values are stored, not in tabular form, but as nodes or leaves on a tree. Data nodes are linked to calculation or analytic nodes that give the data meaning. Branches identify the hierarchy and relationships, even across different data classes. By default, Beacon enables interlinks between the main data class types, including market data, contractual positions, and instrument definitions. With Beacon’s buy and build platform, customers can build any number of new classes on top of the base functionality, connecting data in ways that work best for their business and enabling real-time data sharing across teams without sacrificing accuracy, speed, or robustness.
When a node is changed, either through user input or real-time ticking and streaming data feeds, calculations that depend on that node are flagged for recalculation. Instead of overwriting the old values, Beacon’s unlimited time travel capabilities keep both the old and new entries with appropriate time stamps. Since the old data is still around, you can run reports “as of” any point in time, easily recreating earlier models and reports and catching data entry errors. Configurable settings control which versions of data are used for different functions, making it easy to audit changes, reproduce reports, and quantify the impact of changes.
Since values are recalculated automatically, you may be concerned about governance of the code making the changes. Beacon Platform includes an integrated development environment with sophisticated and secure version control capabilities and software development lifecycle (SDLC) processes for the associated code to ensure that you always know who changed what and when. Beacon is designed so the research environment is automatically connected to your production data.
Dynamic Models Make it Easier to Ask “What if?”
One of the biggest benefits of a true dynamic data architecture is the efficiency of running multiple risk analyses and “what-if” scenarios. Since the graph knows what values are related to each other and what has changed, the platform can make the minimum necessary recalculations, getting results much sooner than static and non-integrated systems. It also makes processing large-scale scenarios faster and easier, with the option to run these calculations in parallel on elastic-compute infrastructure.
Data can be connected to multiple graphs or trees as needed, another technique that helps to keep the data alive. Multiple different types of data can link to the deal model, deals can reference multiple pricing models, multiple trading desks can share information in real time, and analytics can combine all sorts of public and proprietary data. There is no need to create static extracts from the data lake for processing or analysis that quickly become stale or outdated. Risk reports, P&L statements, regulatory extracts, and experimental models can safely reference the same up-to-date values, with their own unique set of outputs. And running these as-of any timeframe is as simple as selecting the desired dates.
Markets are Dynamic. Your Data Should Be, too.
Integrating data, relationships, code, and charts turns static data storage into a living and breathing community of dynamic information. Using Glint, Beacon’s UI framework, you can build applications and visualizations that update your models and risk analyses as markets move or other factors are updated, such as real-time risk servers with automatically changing graphs as market data or calculations change. Or iterate through a neural network aiming to predict future markets or find the next hedging strategies.
Beacon’s dynamic data architecture enables flexible, accurate, and robust access to meaningful information when you need it. Data flows are more efficient, historical values are readily available, and the business is more responsive to unexpected changes or emerging opportunities.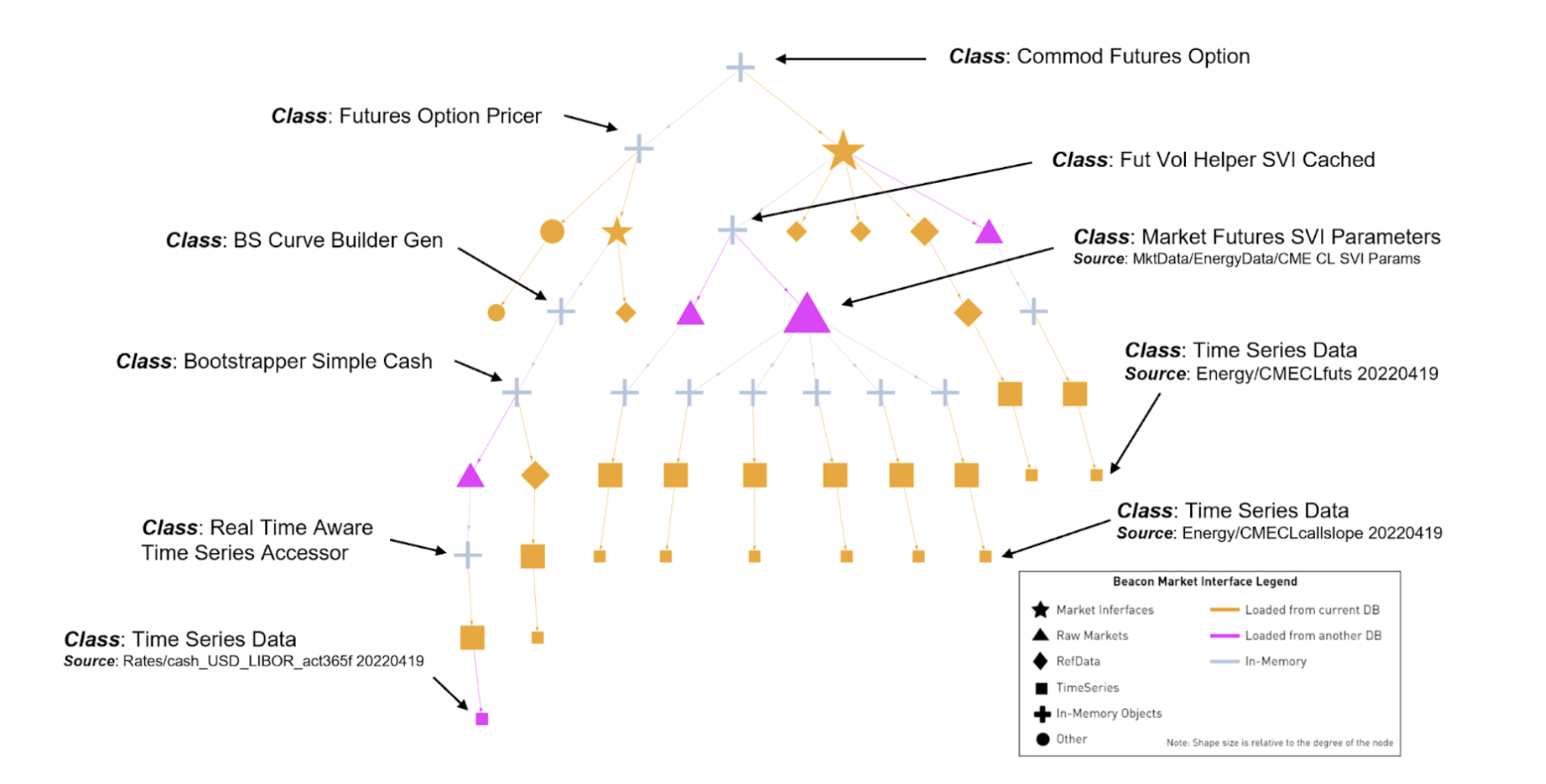 Figure 1. Shows a high level representation of all the dynamic data models used to price a Commodity Futures Option. The shapes show different kinds of dynamic data models, while the colors highlight the different kinds of data. The gray + signs show the instrument calculations and analytics that are derived from the data models.
Figure 1. Shows a high level representation of all the dynamic data models used to price a Commodity Futures Option. The shapes show different kinds of dynamic data models, while the colors highlight the different kinds of data. The gray + signs show the instrument calculations and analytics that are derived from the data models.
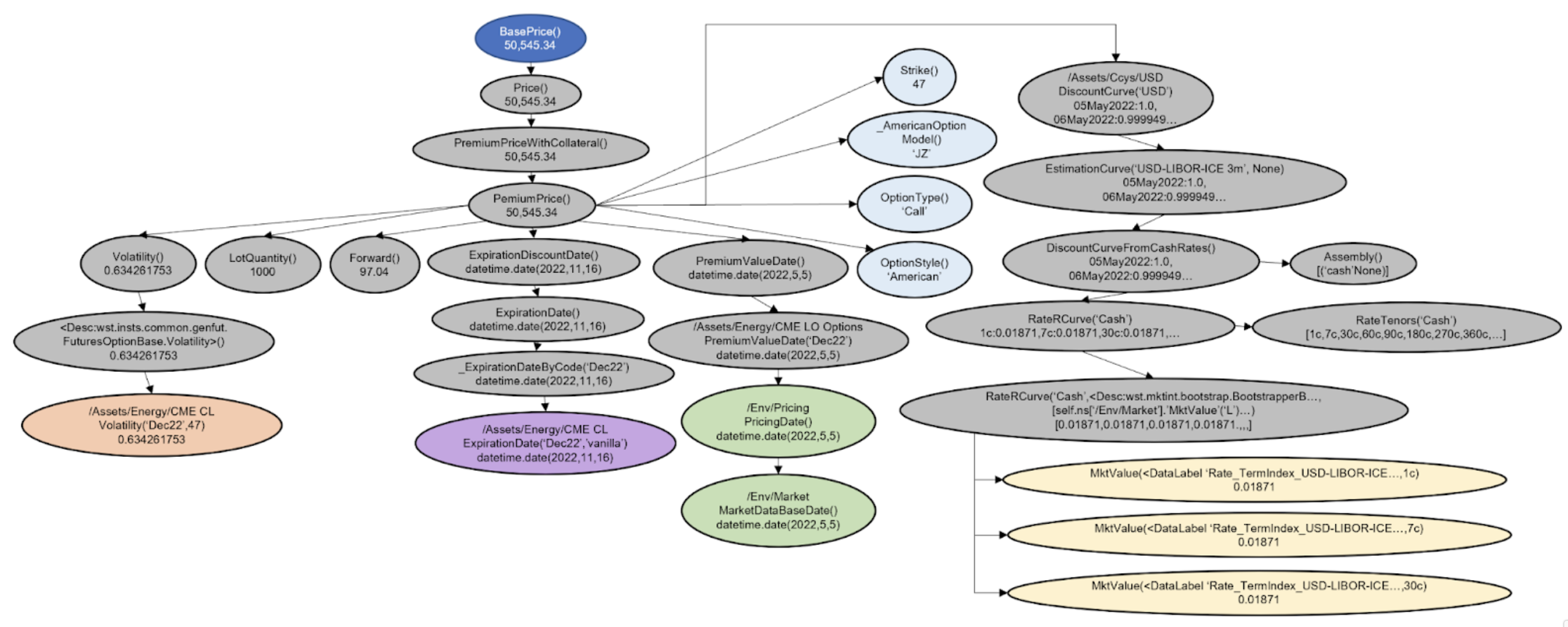
Figure 2. A simplified close up of a few nodes in the graph in Figure 1, highlighting the more granular interactions between different kinds of dynamic data models, and the types of calculations that are often performed on the data to derive the price of a Commodity Futures Option. The light blue nodes represent examples of contractual instrument level data, the light green nodes represent data that can be set at the environment level to impact the pricing of all books and instruments on a trading desk, the purple node is an example of expiration date data on futures contracts, the yellow nodes represent interest rates market data, and the orange node is an example of volatility data.