Machine learning (ML) is becoming an important part of the technology toolkit in financial services. Companies are using these tools to better understand and evaluate models, find investment opportunities, expand portfolios, and adapt to rapidly changing market conditions. Perhaps the biggest challenge is how to integrate machine learning with existing systems and applications.
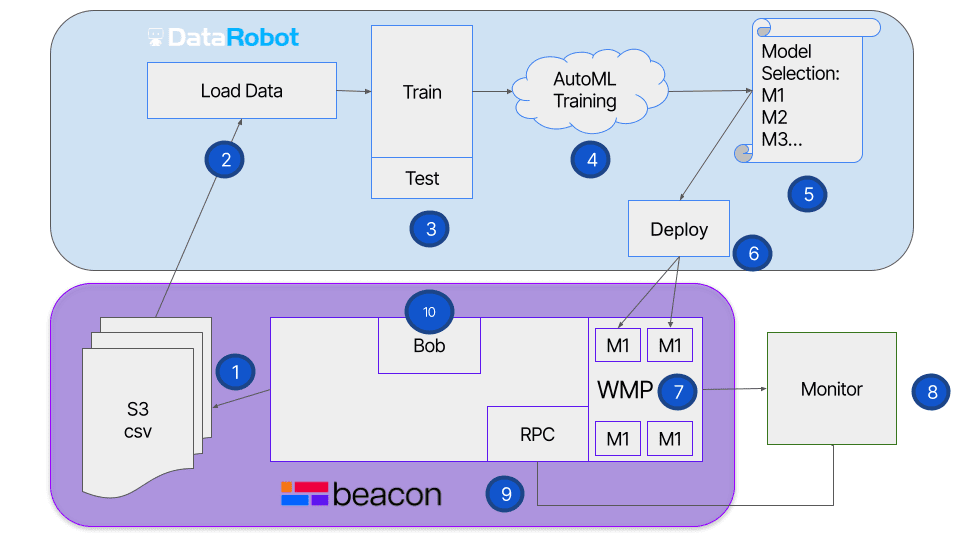
DataRobot offers an open platform that enables data science and quant analyst teams to experiment with multiple ML models, identify key variables that are driving the models, and build impactful strategies from the results. Combined with Beacon’s financial applications and all-in-one open developer experience, these capabilities deliver everything teams need to integrate ML models with existing data, run models on containerized cloud infrastructure against live data, and deploy the desired models into production applications.
In this example, we demonstrate how to use Beacon and DataRobot to get intraday prices for crude and home-heating oil from CME DataMine, train multiple open-source machine-learning training algorithms on the spread between these two commodities to identify the best model, and then evaluate the performance of trading strategies based on the predicted changes in the spread.
Get market data to train the models
The first step in using machine learning is providing an ML algorithm with training data to learn from. Beacon has a wide range of data integrations. In this case, we want a range of intraday prices for crude oil and heating oil. Using Beacon’s CME DataMine plugin, we can quickly select the range and data desired, in this case the details on all of the contracts traded during that time period. Once this data is ingested, we use Beacon Plot to have a quick look at the resulting time series.
Before handing the data over to DataRobot, we are going to package it up with some pre-processing to get it into the desired training format. In this case, bucketing trades in 5-minute blocks and calculating the open, high, low, close, trade count, trade volume, and volume weighted average price for each time interval. Then we export the data for use by DataRobot. We are doing this pre-processing in Beacon because later we want to run the generated model on our elastic compute pool using live production data and we will need to transform the live data the same way we did for the training data.
Train and evaluate multiple models
After ingesting the data into our DataRobot catalog we can start building the desired ML model. This can be done programmatically with Python and R APIs, or via DataRobot’s graphical user interface. First, we select the desired data from the catalog to create the project. Then we select the target variable that we want to predict from the available data. Since this is a time-aware model, we ensure that the models are being trained on the earlier periods and validated on the later ones.
At this point, we can use DataRobot’s AutoML capability to automate the pipeline or workflow of startup tasks and tests to get to the best predictive model. We may not know what type of model will work best, so we can ask the platform to train and test multiple models at the same time. DataRobot then analyzes the data in detail to select the most appropriate machine learning pipelines and, in this case, spawns the training of 20 models simultaneously. The output is a series of blueprints, each of which contains one or more open-source machine learning models and the process they will use to generate the predicted values.
We can tell DataRobot to rank the performance of these generated models on different statistical metrics, such as forecast accuracy or deviation. Reviewing the rankings, we then dig into the details to see what components have gone into the winning models, what variables are driving each model, adjust the thresholds of when the prediction is considered positive, and select one for deployment to Beacon.
Backtest and deploy chosen model
DataRobot generates a package for the selected model and passes it back to Beacon. We can then spin up a job (using Bob, Beacon’s native job scheduler) with the package in its own containerized image on Beacon’s compute infrastructure (using WMP, Beacon’s multiprocessing and compute pool manager), that we can access via a REST API. This gives us a portable prediction server that we can fire data at to generate a range of predictions across the desired timeframe. Using Beacon Notebook (or Jupyter Notebook), we can build a simple trading strategy, in this case, if the spread is predicted to widen, buy 1000 lots, if it is predicted to narrow, then sell 1000 lots, and evaluate its performance as cumulative PnL over time.
Build innovative strategies
In this example we did not expect to generate a fantastic investment strategy (we’ve kept those for ourselves). The objective is to highlight the workflow steps and how our clients can leverage machine learning and create tangible business value. Together, DataRobot and Beacon make it easy to get the necessary market data to train models, train and evaluate multiple models to determine the best option, and backtest and deploy the chosen model into production.
For a deeper dive into how Beacon and DataRobot work together and can accelerate your use of machine learning, watch our video “Scaling Your AI Strategy with Beacon Platform and DataRobot: The Future of Trading and Risk Management“.